把“2026世界杯比分预测更新”做成一张表:用即时指数 + xG + 大数据模型,让判断更有底气
比分不是靠直觉猜出来的,而是被一组可验证的指标“推”出来的。本文把主流数据平台、即时指数与简单统计模型串起来,教你搭建属于自己的比分预测表,并给每轮关键战做出更可解释的判断。

很多人搜索“2026世界杯比分预测更新”,期待的是一个“直接给答案”的比分列表。但真正能长期跑赢情绪波动的,是一套可复用的流程:从数据→到解释→到概率→再到比分。你会发现,最有说服力的预测不是“我觉得会赢”,而是“这些指标告诉我更可能是 2-1 而非 1-0”。
这篇文章偏策略与工具教程:我会把主流数据平台的核心字段、即时指数(含欧指/亚指/大小球的动态变化)、以及简化的大数据建模思路合并,最后给你一张可直接复制的“预测表模板”。
一、数据从哪里来:把“平台信息”变成“可计算字段”
你不需要只依赖一个网站。建议的做法是:用2类信息源交叉验证。
- 比赛表现数据:控球率、射门、射正、xG、xGA、关键传球、对手强度等(常见于赛事数据站/统计页面)。
- 市场与定价信息:欧指/亚指/大小球的开盘与即时变化、热门方向、赔付结构(常见于指数聚合页)。
把它们落到表格里时,最重要的是统一口径:同一指标必须来自同一统计规则;指数要记录“开盘”和“临场/即时”的两个快照。
字段映射建议:最小可用数据集(MVD)
先别贪多。做“能跑起来”的最小数据集,通常只要下面这些列:
| 字段 | 解释 | 用途 |
|---|---|---|
| xG / xGA | 预期进球/预期失球 | 替代“射门数”,更接近机会质量 |
| Shots / SOT | 射门/射正 | 辅助识别“高 xG 是否来自少数机会” |
| Poss% | 控球率 | 看比赛形态,但不直接等于优势 |
| Market Value | 转会身价(阵容强度代理变量) | 长期强弱与深度,适合做先验 |
| FIFA/综合评分 | 国家队与球员能力的结构化评分 | 补足“样本少”的问题 |
| Odds/Handicap/O-U | 欧指、让球、大小球(开盘/即时) | 市场共识与风险定价,做校准与对冲 |
二、关键指标怎么“读”:别把控球率当成胜率
比分预测的核心不是“谁更强”,而是“双方各自能产出多少进球期望”。下面按实战价值从高到低,讲你该怎么读。
1)xG:用机会质量替代“感觉”
xG 可以理解为“如果把同样的射门情境重复很多次,平均能进多少球”。它适合做两件事:
- 识别假强势:控球高、射门多,但 xG 不高,往往是外围尝试堆出来的。
- 识别可持续:连续多场 xG 稳定高,比分波动可能只是运气(门将超神/把握率波动)。
实用技巧:用最近 5 场(或最近 10 场)滚动均值,分别计算 xG_for 与 xG_against,再结合对手强度做轻度修正(见后文模型部分)。
2)场均射门与射正:用来解释“xG 的形状”
同样是 1.6 xG,一种可能来自“16 脚低质量”,另一种来自“6 脚高质量”。前者更依赖偶然与二点球,后者更像体系打穿。建议在表里加入两个派生指标:
- xG/Shot:机会平均质量(越高越像“刀口上起脚”)。
- SOT%(射正率):终结稳定性和射门选择的侧写。
3)控球率:它告诉你“剧本”,不直接告诉你“比分”
控球率更像战术与节奏的镜子:强队压制、弱队收缩反击,都可能让控球率失真。更推荐把控球率作为“比赛形态标签”,例如:
- 高控球+低 xG:可能是对手低位密集,强队缺少禁区渗透。
- 低控球+高 xG:反击质量高,可能更容易出“双方都有进球”。
4)转会身价、FIFA 与俱乐部综合表现:给小样本比赛“加地基”
世界杯周期里,国家队有效样本偏少、对手分布不均。此时用“结构化先验”很有用:
- 转会身价:代表阵容上限与板凳深度,尤其影响赛程密集时的稳定性。
- FIFA/综合评分:把球员能力聚合成可对比的尺度,适合作为模型的基线强度项。
- 俱乐部综合表现:看主力球员在高强度联赛/欧战中的对抗与节奏适应度,用来解释“国家队数据为何偏离”。
三、即时指数怎么结合:把“市场观点”当作校准器
指数的价值不在“跟着买”,而在“帮你发现信息差”。建议你在每场比赛记录三条时间线:开盘、赛前 24 小时、临场 1 小时(或你能拿到的最近快照)。
1)欧指:看概率结构,不只看胜负
把欧指转成隐含概率(简单近似:1/赔率,再归一化)。你会得到“胜-平-负”三项的概率轮廓。对比分预测更有用的是:
- 平局概率抬升:常与“双方进球期望接近”相伴,比分候选更偏 0-0、1-1、2-2。
- 强队胜率升但大小球不动:可能是“更稳的 1-0/2-0”而不是大开大合。
2)大小球与让球:把“总进球”和“分差”拆开看
比分=总进球+分差。大小球更接近“总进球”的定价;让球更接近“分差”的定价。你可以这样用:
- 大小球上调:你的模型若仍输出低总进球,必须解释原因(防守强度、节奏、伤停等)。
- 让球加深但大小球不变:更像强队提升的是“控制力”,比分可能从 1-0 变 2-0,而非 3-1。
四、用简单统计搭建“自己的比分预测表”(可直接照抄)
你不需要复杂机器学习也能做出解释性很强的模型。这里给一个实用框架:先估计双方进球均值 λ(lambda),再用泊松分布生成比分概率,最后与市场指数做校准。
步骤 1:用 xG 估计进球均值(λ)
为每支球队做两个滚动指标(最近 N 场):
- Attack_xG:场均 xG(进攻产出)
- Defense_xGA:场均 xGA(防守允许)
然后给一场对阵(主队 A vs 客队 B)生成基础 λ:
λ_A = 0.5 * Attack_xG_A + 0.5 * Defense_xGA_B λ_B = 0.5 * Attack_xG_B + 0.5 * Defense_xGA_A
想更稳一点,可以加两个轻量修正项:
- 身价/FIFA 强度差:把“长期强弱”转成 ±0.05~0.20 的微调(别过大)。
- 节奏修正:用 Shots 与 xG/Shot 判断是“快节奏乱战”还是“慢节奏磨阵地”,微调总进球。
步骤 2:用泊松分布生成 0-0 到 4-4 的比分概率
泊松分布:P(k)=e^{-λ} * λ^k / k!。在表格里你不必手算,直接用电子表格函数或脚本计算。把 A 的 0~4 球概率与 B 的 0~4 球概率做外积,就得到一个“比分概率矩阵”。
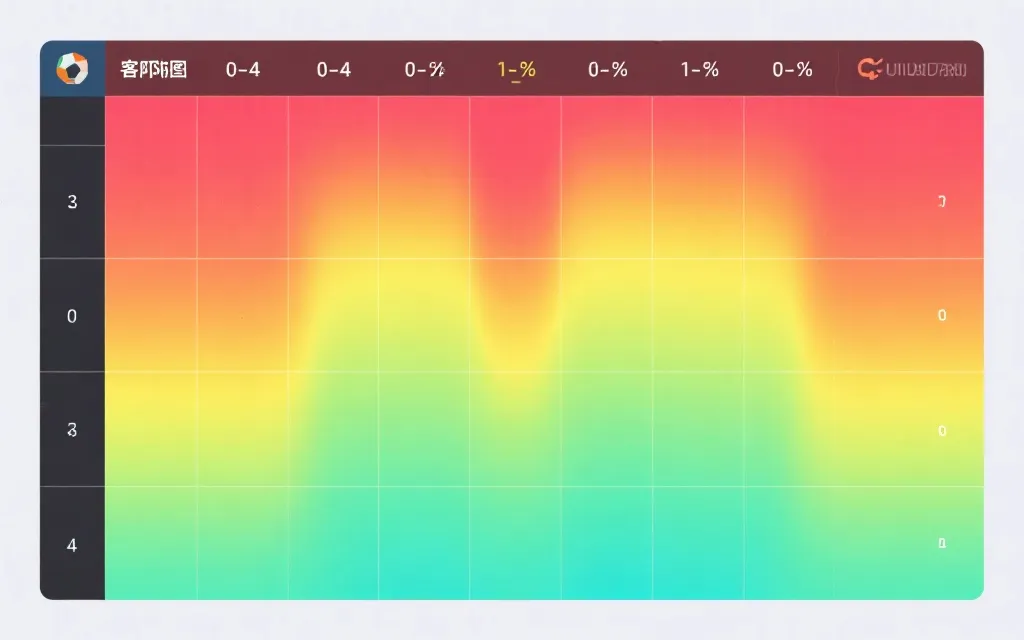
步骤 3:用大小球与欧指做“校准”,让结论更像真实世界
你会遇到一个常见问题:模型算出来的总进球均值与市场大小球不一致。解决方式不是盲从,而是校准:
- 先从你的比分矩阵算出 Over(2.5) 的概率(把所有总进球≥3的格子加总)。
- 再把市场大小球隐含概率换算出来(同样近似 1/赔率并归一)。
- 若差距较大,用一个“总进球缩放系数”调整 λ_A 与 λ_B(例如同时乘以 0.95 或 1.05),直到 Over/Under 概率接近。
同理,你也可以用欧指的胜平负概率,校准“胜/平/负”的汇总概率(把比分矩阵里主胜、平、客胜分别求和)。
五、实战工作流:一场关键战你应该如何写出“可解释结论”
当你做“2026世界杯比分预测更新”时,建议每场都输出同一种结构,读者会觉得你不是在押注情绪,而是在做研究。
- 一句话比赛形态:控球倾向、节奏快慢、谁更可能先手。
- 三条核心证据:最近 N 场 xG/xGA、xG/Shot、对手强度或阵容先验(身价/FIFA)。
- 指数对照:欧指胜平负结构、大小球是否上调、让球是否加深(只描述变化和含义)。
- 模型输出:λ_A、λ_B、最可能的 Top3 比分与各自概率区间。
- 一句话不确定性:比如“若强队首发中轴缺席,λ 会下降 0.15,1-0 概率上升”。
六、可复制的比分预测表模板(字段清单)
你可以用表格/Notion/脚本都行。关键是每场都按同样逻辑填。
- 比赛:A vs B、时间、场地(如可用)
- 数据窗口:最近 N 场(建议 5 或 10),是否包含友谊赛(建议单独标注)
- A:Attack_xG、Defense_xGA、Shots、SOT、xG/Shot、Poss%
- B:Attack_xG、Defense_xGA、Shots、SOT、xG/Shot、Poss%
- 先验:身价差、FIFA/综合评分差、主力球员俱乐部状态概述(简短一句)
- 指数快照:欧指/让球/大小球(开盘、24h、临场)
- 模型:λ_A、λ_B、Over2.5 概率、胜平负概率、Top3 比分
- 结论:主推比分 + 备选比分 + 条件触发(例如“若临场大小球上调则备选 2-1”)
七、常见误区:为什么你“看对了趋势”却“老猜错比分”
- 只看控球:忽略禁区触球与高质量机会,容易高估“传控但不锋利”的球队。
- 只看近期比分:2-0 可能是 0.8 xG 的运气球;0-1 也可能是 2.1 xG 的门前失准。
- 把指数当结论:指数是市场价格,不是事实;它适合做校准与风向识别。
- 模型过拟合:加太多“玄学修正”反而让 λ 失真。宁可少调、可解释、可复盘。
结语:让“预测更新”变成一套可复用的方法
当你把控球率、xG、射门结构、阵容先验与即时指数放进同一张表,比分预测就不再是单点判断,而是一条可复盘的链路。下一次你更新“2026世界杯比分预测更新”,不妨先更新你的表格:你会发现,内容不仅更有说服力,也更容易持续迭代。